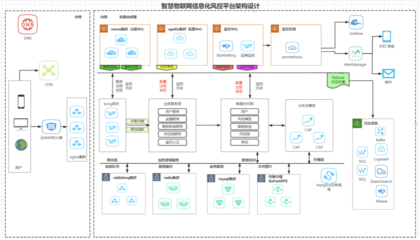
在當(dāng)今大數(shù)據(jù)時(shí)代,企業(yè)對(duì)于數(shù)據(jù)處理的需求日益增長,不僅需要處理海量歷史數(shù)據(jù),還需具備準(zhǔn)實(shí)時(shí)數(shù)據(jù)處理能力。Apache Hadoop作為分布式系統(tǒng)的基礎(chǔ)框架,通過合理架構(gòu)設(shè)計(jì)可實(shí)現(xiàn)準(zhǔn)實(shí)時(shí)數(shù)據(jù)處理,以下介紹幾種典型的架構(gòu)模式。
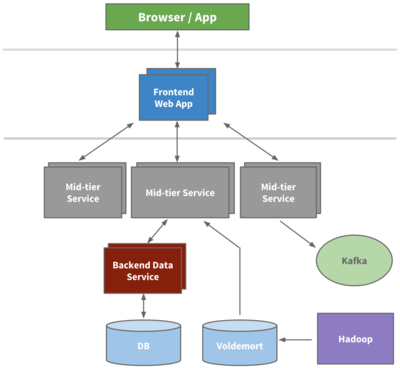
Lambda架構(gòu)是最經(jīng)典的準(zhǔn)實(shí)時(shí)數(shù)據(jù)處理模式。該架構(gòu)包含批處理層、速度層和服務(wù)層三層結(jié)構(gòu)。批處理層使用Hadoop MapReduce或Spark處理全量數(shù)據(jù),保證數(shù)據(jù)準(zhǔn)確性;速度層通過Storm或Spark Streaming處理實(shí)時(shí)數(shù)據(jù)流,提供低延遲響應(yīng);服務(wù)層則合并兩層結(jié)果對(duì)外提供查詢服務(wù)。這種架構(gòu)兼顧了數(shù)據(jù)準(zhǔn)確性和處理時(shí)效性,但需要維護(hù)兩套代碼邏輯。
Kappa架構(gòu)是Lambda架構(gòu)的簡化版本。該架構(gòu)取消了批處理層,完全基于流式處理。通過將歷史數(shù)據(jù)重新注入流處理系統(tǒng),使用同一套代碼邏輯處理歷史和實(shí)時(shí)數(shù)據(jù)。Kafka通常作為消息隊(duì)列,配合Spark Streaming或Flink實(shí)現(xiàn)數(shù)據(jù)流動(dòng)。這種架構(gòu)簡化了系統(tǒng)復(fù)雜度,但要求流處理系統(tǒng)具備精確一次語義和狀態(tài)管理能力。
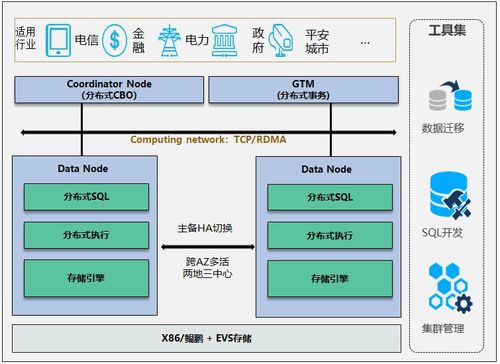
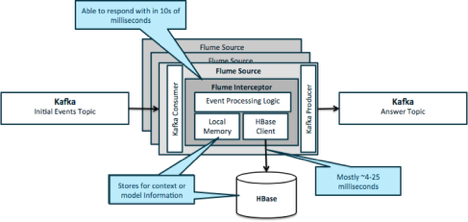
基于Hadoop生態(tài)的混合架構(gòu)也值得關(guān)注。例如使用HDFS存儲(chǔ)歷史數(shù)據(jù),HBase提供實(shí)時(shí)查詢,Kafka作為數(shù)據(jù)管道,Spark進(jìn)行流批一體處理。這種架構(gòu)充分利用Hadoop生態(tài)組件,通過合理組合實(shí)現(xiàn)準(zhǔn)實(shí)時(shí)數(shù)據(jù)處理需求。
在實(shí)際應(yīng)用中,架構(gòu)選擇需考慮業(yè)務(wù)場景、數(shù)據(jù)規(guī)模、時(shí)效要求等因素。無論采用何種架構(gòu),都需要關(guān)注數(shù)據(jù)一致性、系統(tǒng)可擴(kuò)展性和運(yùn)維復(fù)雜度等問題。隨著技術(shù)的發(fā)展,基于Hadoop的準(zhǔn)實(shí)時(shí)數(shù)據(jù)處理架構(gòu)將持續(xù)演進(jìn),為企業(yè)數(shù)據(jù)驅(qū)動(dòng)決策提供更強(qiáng)有力的支撐。